Appendix B — Appendix B. APL features
The book A Programming Language was published by mathematician Kenneth E. Iverson in 1962. He wanted a formal language that would look like what mathematicians write on chalkboards. The then-unnamed language would later take its name from the first letters of the words in the book’s title. It was little-known until 1964, when a formal description of the just-announced IBM System/360 in the IBM Systems Journal used APL notation. (Around the same time, Iverson’s associate Adin Falkoff gave a talk on APL to a New York Association for Computing Machinery chapter, with an excited 14-year-old Brian Harvey in the audience.) But it wasn’t until 1966 that the first public implementation of the language for the System/360 was published by IBM. (It was called “APL\360 ” because the normal slash character / represents the “reduce” operator in APL, while backslash is “expand.”)
The crucial idea behind APL is that mathematicians think about collections of numbers, one-dimensional vectors and two-dimensional matrices , as valid objects in themselves, what computer scientists later learned to call “first class data .” A mathematician who wants to add two vectors writes v1 + v2, not “for i = 1 to length(v1), result[i]=v1[i]+v2[i].” Same for a programmer using APL.
There are three kinds of function in APL: scalar functions , mixed functions , and operators . A scalar function is one whose natural domain is individual numbers or text characters. A mixed function is one whose domain includes arrays (vectors, matrices, or higher-dimensional collections). In Snap!, scalar functions are generally found in the green Operators palette, while mixed functions are in the red Lists palette. The third category, confusingly for Snap! users, is called operators in APL, but corresponds to what we call higher order functions : functions whose domain includes functions.
Snap! hyperblocks are scalar functions that behave like APL scalar functions: they can be called with arrays as inputs, and the underlying function is applied to each number in the arrays. (If the function is monadic, meaning that it takes one input, then there’s no complexity to this idea. Take the square root of an array, and you are taking the square root of each number in the array. If the function is dyadic, taking two inputs, then the two arrays must have the same shape. Snap! is more forgiving than APL; if the arrays don’t agree in number of dimensions, called the rank of the array, the lower-rank array is matched repeatedly with subsets of the higher-rank one; if they don’t agree in length along one dimension, the result has the shorter length and some of the numbers in the longer-length array are ignored. An exception in both languages is that if one of the two inputs is a scalar, then it is matched with every number in the other array input.)
As explained in Section IV.F, this termwise extension of scalar functions is the main APL-like feature built into Snap! itself. We also include an extension of the item block to address multiple dimensions, an extension to the length block with five list functions from APL, and a new primitive reshape block . The APL library extends the implementation of APL features to include a few missing scalar functions and several missing mixed functions and operators.
Programming in APL really is very different in style from programming in other languages, even Snap!. This appendix can’t hope to be a complete reference for APL, let alone a tutorial. If you’re interested, find one of those in a library or a (probably used) bookstore, read it, and do the exercises. Sorry to sound like a teacher, but the notation is sufficiently weird as to take a lot of practice before you start to think in APL.
A note on versions: There is a widely standardized APL2, several idiosyncratic extensions, and a successor language named J. The latter uses plain ASCII characters, unlike the ones with APL in their names, which use the mathematician’s character set, with Greek letters, typestyles (boldface and/or italics in books; underlined, upper case, or lower case in APL) as loose type declarations, and symbols not part of anyone’s alphabet, such as ⌊ for floor and ⌈ for ceiling. To use the original APL, you needed expensive special computer terminals. (This was before you could download fonts in software. Today the more unusual APL characters are in Unicode at U+2336 to U+2395.) The character set was probably the main reason APL didn’t take over the world. APL2 has a lot to recommend it for Snap! users, mainly because it moves from the original APL idea that all arrays must be uniform in dimension, and the elements of arrays must be numbers or single text characters, to our idea that a list can be an element of another list, and that such elements don’t all have to have the same dimensions. Nevertheless, its mechanism for allowing both old-style APL arrays and more general “nested arrays” is complicated and hard for an APL beginner (probably all but two or three Snap! users) to understand. So we are starting with plain APL. If it turns out to be wildly popular, we may decide later to include APL2 features.
Here are some of the guiding ideas in the design of the APL library:
Goal: Enable interested Snap! users to learn the feel and style of APL programming. It’s really worth the effort. For example, we didn’t hyperize the = block because Snap! users expect it to give a single yes-or-no answer about the equality of two complete structures , whatever their types and shapes. In APL, = is a scalar function; it compares two numbers or two characters. How could APL users live without the ability to ask if two structures are equal? Because in APL you can say ∧/,a=b to get that answer. Reading from right to left, a=b reports an array of Booleans (represented in APL as 0 for False, 1 for True); the comma operator turns the shape of the array into a simple vector; and ∧/ means “reduce with and”; “reduce” is our combine function. That six-character program is much less effort than the equivalent
 in Snap!. Note in passing that if you wanted to know how many corresponding elements of the two arrays are equal, you’d just use +/ instead of ∧/. Note also that our APLish blocks are a little verbose, because they include up to three notations for the function: the usual Snap! name (e.g., flatten), the name APL programmers use when talking about it (ravel ), and, in yellow type, the symbol used in actual APL code (,). We’re not consistent about it;
in Snap!. Note in passing that if you wanted to know how many corresponding elements of the two arrays are equal, you’d just use +/ instead of ∧/. Note also that our APLish blocks are a little verbose, because they include up to three notations for the function: the usual Snap! name (e.g., flatten), the name APL programmers use when talking about it (ravel ), and, in yellow type, the symbol used in actual APL code (,). We’re not consistent about it;  seems self-documenting. And LCM (and) is different even though it has two names; it turns out that if you represent Boolean values as 0 and 1, then the algorithm to compute the least common multiple of two integers computes the and function if the two inputs happen to be Boolean. Including the APL symbols serves two purposes: the two or three Snap! users who’ve actually programmed in APL will be sure what function they’re using, but more importantly, the ones who are reading an APL tutorial while building programs in Snap! will find the block that matches the APL they’re reading.
seems self-documenting. And LCM (and) is different even though it has two names; it turns out that if you represent Boolean values as 0 and 1, then the algorithm to compute the least common multiple of two integers computes the and function if the two inputs happen to be Boolean. Including the APL symbols serves two purposes: the two or three Snap! users who’ve actually programmed in APL will be sure what function they’re using, but more importantly, the ones who are reading an APL tutorial while building programs in Snap! will find the block that matches the APL they’re reading.Goal: Bring the best and most general APL ideas into “mainstream” Snap! programming style. Media computation , in particular, becomes much simpler when scalar functions can be applied to an entire picture or sound. Yes, map provides essentially the same capability, but the notation gets complicated if you want to map over columns rather than rows. Also, Snap! lists are fundamentally one-dimensional, but real data often have more dimensions. A Snap! programmer has to be thinking all the time about the convention that we represent a matrix as a list of rows, each of which is a list of individual cells. That is, row 23 of a spreadsheet is item 23 of spreadsheet, but column 23 is map (item 23 of _) over spreadsheet. APL treats rows and columns more symmetrically.
Non-goal: Allow programs written originally in APL to run in Snap! essentially unchanged. For example, in APL the atomic text unit is a single character, and strings of characters are lists. We treat a text string as scalar, and that isn’t going to change. Because APL programmers rarely use conditionals, instead computing functions involving arrays of Boolean values to achieve the same effect, the notation they do have for conditionals is primitive (in the sense of Paleolithic , not in the sense of built in). We’re not changing ours.
Non-goal: Emulate the terse APL syntax. It’s too bad, in a way; as noted above, the terseness of expressing a computation affects APL programmers’ sense of what’s difficult and what isn’t. But you can’t say “terse” and “block language” in the same sentence. Our whole raison d’être is to make it possible to build a program without having to memorize the syntax or the names of functions, and to allow those names to be long enough to be self-documenting. And APL’s syntax has its own issues, of which the biggest is that it’s hard to use functions with more than two inputs; because most mathematical dyadic functions use infix notation (the function symbol between the two inputs), the notion of “left argument” and “right argument” is universal in APL documentation. The thing people most complain about, that there is no operator precedence (like the multiplication-before-addition rule in normal arithmetic notation), really doesn’t turn out to be a problem. Function grouping is strictly right to left, so 2×3+4 means two times seven, not six plus four. That takes some getting used to, but it really doesn’t take long if you immerse yourself in APL. The reason is that there are too many infix operators for people to memorize a precedence table. But in any case, block notation eliminates the problem, especially with Snap!’s zebra coloring. You can see and control the grouping by which block is inside which other block’s input slot. Another problem with APL’s syntax is that it bends over backward not to have reserved words, as opposed to Fortran, its main competition back then. So the dyadic ○ “circular functions” function uses the left argument to select a trig function. 1○x is sin(x), 2○x is cos(x), and so on. ‾1○x is arcsin(x). What’s 0○x? Glad you asked; it’s\\\sqrt{1 - x^{2}}.
Boolean values
Snap! uses distinct Boolean values true and false that are different from other data types. APL uses 1 and 0, respectively. The APL style of programming depends heavily on doing arithmetic on Booleans, although their conditionals insist on only 0 or 1 in a Boolean input slot, not other numbers. Snap! arithmetic functions treat false as 0 and true as 1, so our APL library tries to report Snap! Boolean values from predicate functions.
Scalar functions

These are the scalar functions in the APL library. Most of them are straightforward to figure out. The scalar = block provides an APL-style version of = (and other exceptions) as a hyperblock that extends termwise to arrays. Join, the only non-predicate non-hyper scalar primitive, has its own scalar join block . 7 deal 52 reports a random vector of seven numbers from 1 to 52 with no repetitions, as in dealing a hand of cards. Signum of a number reports 1 if the number is positive, 0 if it’s zero, or -1 if it’s negative. Roll 6 reports a random roll of a six-sided die. To roll 8 dice, use  , which would look much more pleasant as ?8⍴6. But perhaps our version is more instantly readable by someone who didn’t grow up with APL. All the library functions have help messages available.
, which would look much more pleasant as ?8⍴6. But perhaps our version is more instantly readable by someone who didn’t grow up with APL. All the library functions have help messages available.
Mixed functions
Mixed functions include lists in their natural domain or range. That is, one or both of its inputs must be a list, or it always reports a list. Sometimes both inputs are naturally lists; sometimes one input of a dyadic mixed function is naturally a scalar, and the function treats a list in that input slot as an implicit map, as for scalar functions. This means you have to learn the rule for each mixed function individually.
 The shape of function takes any input and reports a vector of the maximum size of the structure along each dimension. For a vector, it returns a list of length 1 containing the length of the input. For a matrix, it returns a two-item list of the number of rows and number of columns of the input. And so on for higher dimensions. If the input isn’t a list at all, then it has zero dimensions, and shape of reports an empty vector. Equivalent to the dimensions of primitive, as of 6.6.
The shape of function takes any input and reports a vector of the maximum size of the structure along each dimension. For a vector, it returns a list of length 1 containing the length of the input. For a matrix, it returns a two-item list of the number of rows and number of columns of the input. And so on for higher dimensions. If the input isn’t a list at all, then it has zero dimensions, and shape of reports an empty vector. Equivalent to the dimensions of primitive, as of 6.6.

 Rank of isn’t an actual APL primitive, but the composition ⍴⍴ (shape of shape of a structure), which reports the number of dimensions of the structure (the length of its shape vector), is too useful to omit. (It’s very easy to type the same character twice on the APL keyboard, but less easy to drag blocks together.) Equivalent to the rank of primitive, as of 6.6.
Rank of isn’t an actual APL primitive, but the composition ⍴⍴ (shape of shape of a structure), which reports the number of dimensions of the structure (the length of its shape vector), is too useful to omit. (It’s very easy to type the same character twice on the APL keyboard, but less easy to drag blocks together.) Equivalent to the rank of primitive, as of 6.6.

Reshape takes a shape vector (such as shape might report) on the left and any structure on the right. It ignores the shape of the right input, stringing the atomic elements into a vector in row-major order (that is, all of the first row left to right, then all of the second row, etc.). (The primitive reshape takes the inputs in the other order.) It then reports an array with the shape specified by the first input containing the items of the second:

If the right input has more atomic elements than are required by the left-input shape vector, the excess are ignored without reporting an error. If the right input has too few atomic elements, the process of filling the reported array starts again from the first element. This is most useful in the specific case of an atomic right input, which produces an array of any desired shape all of whose atomic elements are equal. But other cases are sometimes useful too:


 Flatten takes an arbitrary structure as input and reports a vector of its atomic elements in row-major order. Lispians call this flattening the structure, but APLers call it “ravel” because of the metaphor of pulling on a ball of yarn, so what they really mean is “unravel.” (But the snarky sound of that is uncalled-for, because a more advanced version that we might implement someday is more like raveling.) One APL idiom is to apply this to a scalar in order to turn it into a one-element vector, but we can’t use it that way because you can’t type a scalar value into the List-type input slot. Equivalent to the primitive flatten of block.
Flatten takes an arbitrary structure as input and reports a vector of its atomic elements in row-major order. Lispians call this flattening the structure, but APLers call it “ravel” because of the metaphor of pulling on a ball of yarn, so what they really mean is “unravel.” (But the snarky sound of that is uncalled-for, because a more advanced version that we might implement someday is more like raveling.) One APL idiom is to apply this to a scalar in order to turn it into a one-element vector, but we can’t use it that way because you can’t type a scalar value into the List-type input slot. Equivalent to the primitive flatten of block.

Catenate is like our primitive append, with two differences: First, if either input is a scalar, it is treated like a one-item vector. Second, if the two inputs are of different rank, the catenate function is recursively mapped over the higher-rank input:

Catenate vertically is similar, but it adds new rows instead of adding new columns.

Integers (I think that’s what it stands for, although APLers just say “iota”) takes a positive integer input and reports a vector of the integers from 1 to the input. This is an example of a function classed as “mixed” not because of its domain but because of its range. The difference between this block and the primitive numbers from block is in its treatment of lists as inputs. Numbers from is a hyperblock, applying itself to each item of its input list:

Iota has a special meaning for list inputs: The input must be a shape vector; the result is an array with that shape in which each item is a list of the indices of the cell along each dimension. A picture is worth 103 words, but Snap! isn’t so good at displaying arrays with more than two dimensions, so here we reduce each cell’s index list to a string:

 Dyadic iota is like the index of primitive except for its handling of multi-dimensional arrays. It looks only for atomic elements, so a vector in the second input doesn’t mean to search for that vector as a row of a matrix, which is what it means to index of, but rather to look separately for each item of the vector, and report a list of the locations of each item. If the first input is a multi-dimensional array, then the location of an item is a vector with the indices along each row.
Dyadic iota is like the index of primitive except for its handling of multi-dimensional arrays. It looks only for atomic elements, so a vector in the second input doesn’t mean to search for that vector as a row of a matrix, which is what it means to index of, but rather to look separately for each item of the vector, and report a list of the locations of each item. If the first input is a multi-dimensional array, then the location of an item is a vector with the indices along each row.

In this example, the 4 is in the second row, second column. (This is actually an extension of APL iota, which is more like a hyperized index of.) Generalizing, if the rank of the second input is less than the rank of the first input by two or more, then iota looks for the entire second input in the first input. The reported position is a vector whose length is equal to the difference between the two ranks. If the rank of the second input is one less than the rank of the first, the reported value is a scalar, the index of the entire second input in the first.

However, if the two ranks are equal, then the block is hyperized; each item of the second input is located in the first input. As the next example shows, only the first instance of each item is found (e.g., the 1 in position 2, not the 1 in position 4); if an item does not occur in the left input, what is reported is one more than the length of the left input (here, 8).

Why the strange design decision to report length+1 when something isn’t found, instead of a more obvious flag value such as 0 or false? Here’s why:
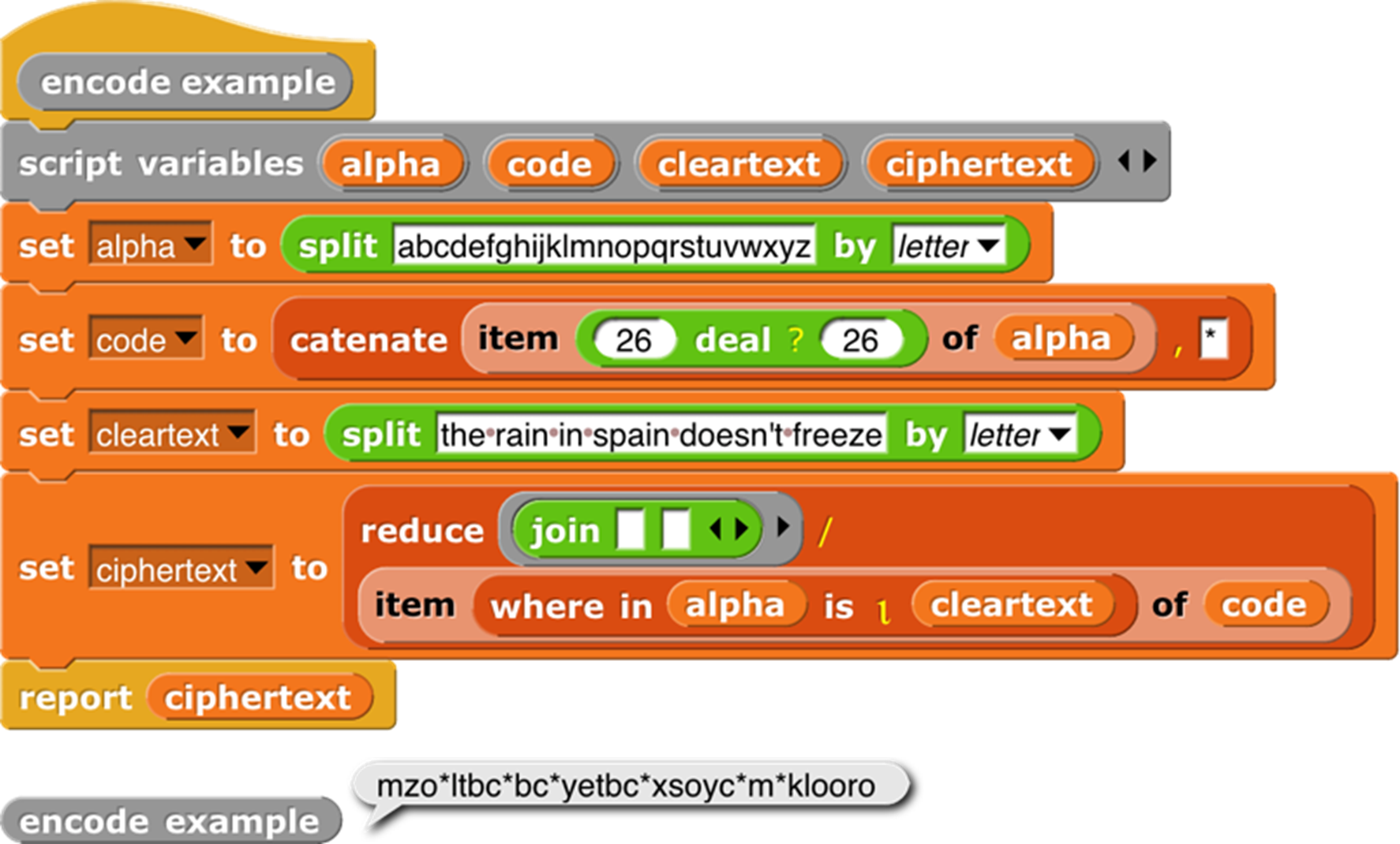
Note that code has 27 items, not 26. The asterisk at the end is the ciphertext is the translation of all non-alphabet characters (spaces and the apostrophe in “doesn’t”). This is a silly example, because it makes up a random cipher every time it’s called, and it doesn’t report the cipher, so the recipient can’t decipher the message. And you wouldn’t want to make the spaces in the message so obvious. But despite being silly, the example shows the benefit of reporting length+1 as the position of items not found.

The contained in block is like a hyperized contains with the input order reversed. It reports an array of Booleans the same shape as the left input. The shape of the right input doesn’t matter; the block looks only for atomic elements.

 The blocks grade up and grade down are used for sorting data. Given an array as input, it reports a vector of the indices in which the items (the rows, if a matrix) should be rearranged in order to be sorted. This will be clearer with an example:
The blocks grade up and grade down are used for sorting data. Given an array as input, it reports a vector of the indices in which the items (the rows, if a matrix) should be rearranged in order to be sorted. This will be clearer with an example:
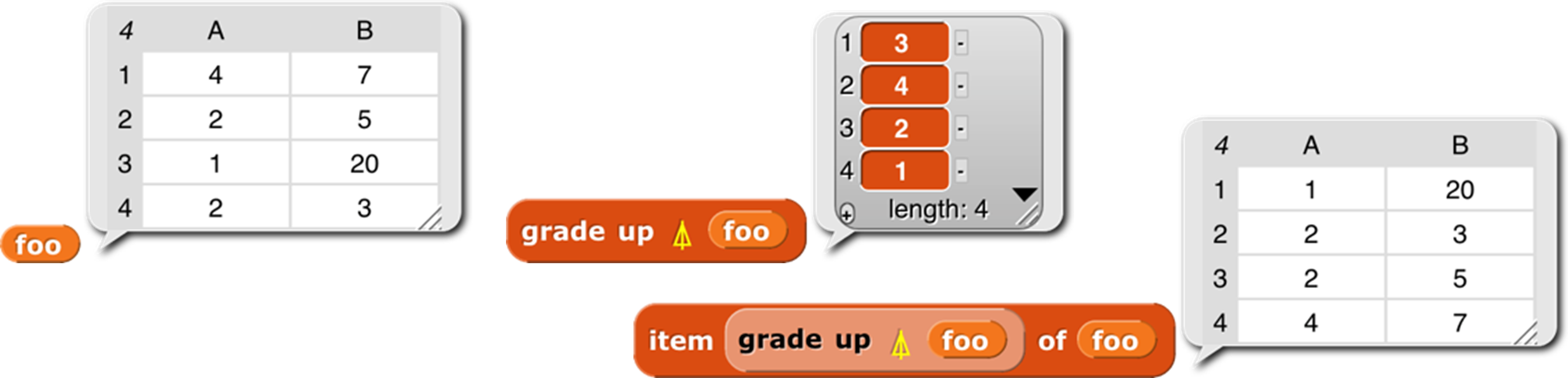
The result from grade up tells us that item 3 of foo comes first in sorted order, then item 4, then 2, then 1. When we actually select items of foo based on this ordering, we get the desired sorted version. The result reported by grade down is almost the reverse of that from grade up, but not quite, if there are equal items in the list. (The sort is stable, so if there are equal items, then whichever comes first in the input list will also be first in the sorted list.)
Why this two-step process? Why not just have a sort primitive in APL? One answer is that in a database application you might want to sort one array based on the order of another array:
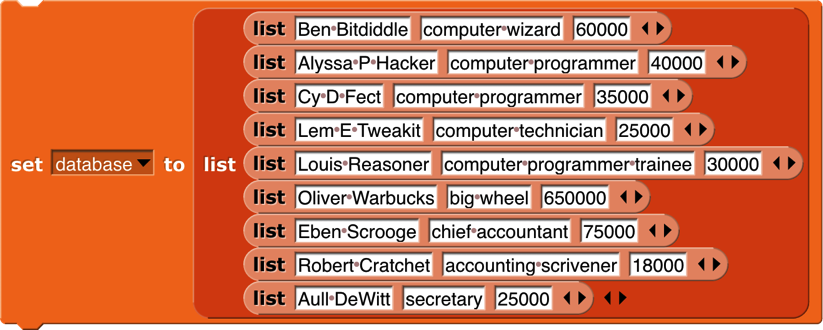
This is the list of employees of a small company. (Taken from Structure and Interpretation of Computer Programs by Abelson and Sussman. Creative Commons licensed.) Each of the smaller lists contains a person’s name, job title, and yearly salary. We would like to sort the employees’ names in big-to-small order of salary. First we extract column 3 of the database, the salaries:

Then we use grade down to get the reordering indices:
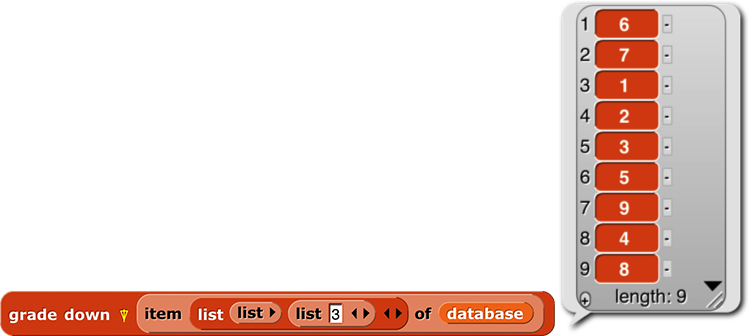
At this point we could use the index vector to sort the salaries:
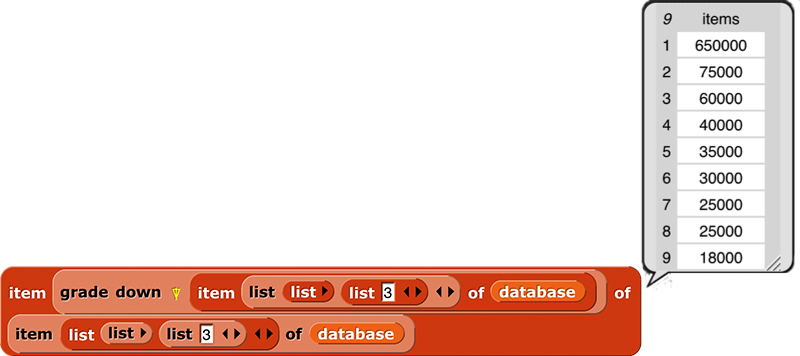
But what we actually want is a list of names, sorted by salary:
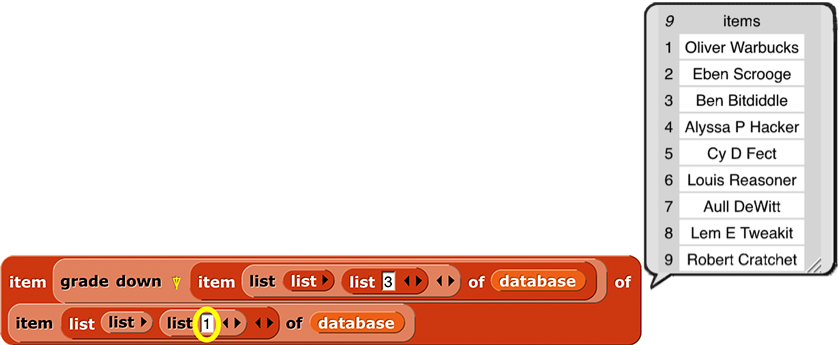
By taking the index vector from grade down of column 3 and telling item to apply it to column 1, we get what we set out to find. As usual the code is more elegant in APL: database[⍒database[;3];1].
In case you’ve forgotten,  or
or  would select the third row of the database; we need the list 3 in the second input slot of the outer list to select by columns rather than by rows.
would select the third row of the database; we need the list 3 in the second input slot of the outer list to select by columns rather than by rows.

Select (if take ) or select all but (if drop ) the first (if n>0) or last (if n<0) |n| items from a vector, or rows from a matrix. Alternatively, if the left input is a two-item vector, select rows with the first item and columns with the second.

The compress block selects a subset of its right input based on the Boolean values in its left input, which must be a vector of Booleans whose length equals the length of the array (the number of rows, for a matrix) in the right input. The block reports an array of the same rank as the right input, but containing only those rows whose corresponding Boolean value is true. The columns version ⌿ is the same but selecting columns rather than selecting rows.
A word about the possibly confusing names of these blocks: There are two ways to think about what they do. Take the standard / version, to avoid talking about both at once. One way to think about it is that it selects some of the rows. The other way is that it shortens the columns. For Lispians, which includes you since you’ve learned about keep, the natural way to think about / is that it keeps some of the rows. Since we represent a matrix as a list of rows, that also fits with how this function is implemented. (Read the code; you’ll find a keep inside.) But APL people think about it the other way, so when you read APL documentation, / is described as operating on the last dimension (the columns), while ⌿ is described as operating on rows. We were more than a month into this project before I understood all this. You get long block names so it won’t take you a month!


 Don’t confuse this block with the reduce block , whose APL symbol is also a slash. In that block, what comes to the left of the slash is a dyadic combining function; it’s the APL equivalent of combine. This block is more nearly equivalent to keep. But keep takes a predicate function as input, and calls the function for each item of the second input. With compress, the predicate function, if any, has already been called on all the items of the right input in parallel, resulting in a vector of Boolean values. This is a typical APL move; since hyperblocks are equivalent to an implicit map, it’s easy to make the vector of Booleans, because any scalar function, including predicates, can be applied to a list instead of to a scalar. The reason both blocks use the / character is that both of them reduce the size of the input array, although in different ways.
Don’t confuse this block with the reduce block , whose APL symbol is also a slash. In that block, what comes to the left of the slash is a dyadic combining function; it’s the APL equivalent of combine. This block is more nearly equivalent to keep. But keep takes a predicate function as input, and calls the function for each item of the second input. With compress, the predicate function, if any, has already been called on all the items of the right input in parallel, resulting in a vector of Boolean values. This is a typical APL move; since hyperblocks are equivalent to an implicit map, it’s easy to make the vector of Booleans, because any scalar function, including predicates, can be applied to a list instead of to a scalar. The reason both blocks use the / character is that both of them reduce the size of the input array, although in different ways.
The reverse row order , reverse column order , and transpose blocks form a group: the group of reflections of a matrix. The APL symbols are all a circle with a line through it; the lines are the different axes of reflection. So the reverse row order block reverses which row is where; the reverse column order block reverses which column is where; and the transpose block turns rows into columns and vice versa:

Except for reverse row order, these work only on full arrays, not ragged-right lists of lists, because the result of the other two would be an array in which some rows had “holes”: items 1 and 3 exist, but not item 2. We don’t have a representation for that. (In APL, all arrays are full, so it’s even more restrictive.)
Higher order functions
The final category of function is operators —APL higher order functions . APL has no explicit map function, because the hyperblock capability serves much the same need. But APL2 did add an explicit map, which we might get around to adding to the library next time around. Its symbol is ¨ (diaeresis or umlaut).
The APL equivalent of keep is compress, but it’s not a higher order function. You create a vector of Booleans (0s and 1s, in APL) before applying the function to the array you want to compress.
But APL does have a higher order version of combine:

The reduce block works just like combine, taking a dyadic function and a list. The / version translates each row to a single value; the ⌿ version translates each column to a single value. That’s the only way to think about it from the perspective of combining individual elements: you are adding up, or whatever the function is, the numbers in a single row (/) or in a single column (⌿). But APLers think of a matrix as made up of vectors, either row vectors or column vectors. And if you think of what these blocks do as adding vectors, rather than adding individual numbers, it’s clear that in


the vector (10, 26, 42) is the sum of column vectors (1, 5, 9)+(2, 6, 10)+(3, 7, 11)+(4, 8, 12). In pre-6.0 Snap!, we’d get the same result this way:

mapping over the rows of the matrix, applying combine to each row. Combining rows, reducing column vectors.
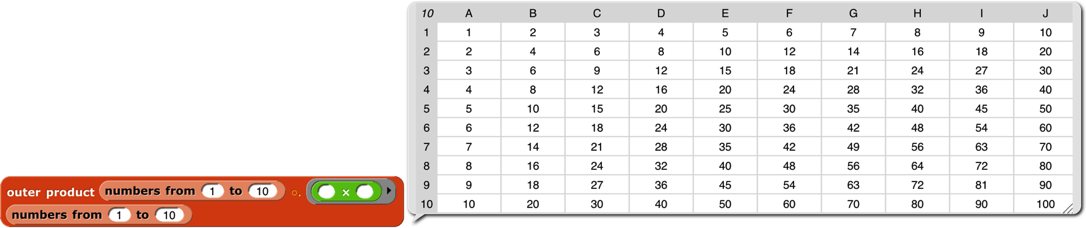
 The outer product block takes two arrays (vectors, typically) and a dyadic scalar function as inputs. It reports an array whose rank is the sum of the ranks of the inputs (so, typically a matrix), in which each item is the result of applying the function to an atomic element of each array. The third element of the second row of the result is the value reported by the function with the second element of the left input and the third element of the right input. (The APL symbol ◦. is pronounced “jot dot.”) The way to think about this block is “multiplication table ” from elementary school:
The outer product block takes two arrays (vectors, typically) and a dyadic scalar function as inputs. It reports an array whose rank is the sum of the ranks of the inputs (so, typically a matrix), in which each item is the result of applying the function to an atomic element of each array. The third element of the second row of the result is the value reported by the function with the second element of the left input and the third element of the right input. (The APL symbol ◦. is pronounced “jot dot.”) The way to think about this block is “multiplication table ” from elementary school:
 The inner product block takes two matrices and two operations as input. The number of columns in the left matrix must equal the number of rows in the right matrix. When the two operations are + and ×, this is the matrix multiplication familiar to mathematicians:
The inner product block takes two matrices and two operations as input. The number of columns in the left matrix must equal the number of rows in the right matrix. When the two operations are + and ×, this is the matrix multiplication familiar to mathematicians:

But other operations can be used. One common inner product is ∨.∧ (“or dot and”) applied to Boolean matrices, to find rows and columns that have corresponding items in common.
 The printable block isn’t an APL function; it’s an aid to exploring APL-in-Snap!. It transforms arrays to a compact representation that still makes the structure clear:
The printable block isn’t an APL function; it’s an aid to exploring APL-in-Snap!. It transforms arrays to a compact representation that still makes the structure clear:

Experts will recognize this as the Lisp representation of list structure,
[1] One of the hat blocks, the generic “when anything” block , is subtly different from the others. When the stop sign is clicked, or when a project or sprite is loaded, this block doesn’t test whether the condition in its hexagonal input slot is true, so the script beneath it will not run, until some other script in the project runs (because, for example, you click the green flag). When generic when blocks are disabled, the stop sign will be square instead of octagonal.
[2] The hide variable and show variable block s can also be used to hide and show primitives in the palette. The pulldown menu doesn’t include primitive blocks, but there’s a generally useful technique to give a block input values it wasn’t expecting using run or call:
In order to use a block as an input this way, you must explicitly put a ring around it, by right-clicking on it and choosing ringify. More about rings in Chapter VI.
[3] This use of the word “prototype” is unrelated to the prototyping object oriented programming discussed later.
[4] Note to users of earlier versions: From the beginning, there has been a tension in our work between the desire to provide tools such as for (used in this example) and the higher order functions introduced on the next page as primitives, to be used as easily as other primitives, and the desire to show how readily such tools can be implemented in Snap! itself. This is one instance of our general pedagogic understanding that learners should both use abstractions and be permitted to see beneath the abstraction barrier. Until version 5.0, we used the uneasy compromise of a library of tools written in Snap! and easily, but not easily enough, loaded into a project. By not loading the tools, users or teachers could explore how to program them. In 5.0 we made them true primitives, partly because that’s what some of us wanted all along and partly because of the increasing importance of fast performance as we explore “big data” and media computation. But this is not the end of the story for us. In a later version, after we get the design firmed up, we intend to introduce “hybrid” primitives, implemented in high speed Javascript but with an “Edit” option that will open, not the primitive implementation, but the version written in Snap!. The trick is to ensure that this can be done without dramatically slowing users’ projects.
[5] In Scratch, every block that takes a Text-type input has a default value that makes the rectangles for text wider than tall. The blocks that aren’t specifically about text either are of Number type or have no default value, so those rectangles are taller than wide. At first some of us (bh) thought that Text was a separate type that always had a wide input slot; it turns out that this isn’t true in Scratch (delete the default text and the rectangle narrows), but we thought it a good idea anyway, so we allow Text-shaped boxes even for empty input slots. (This is why Text comes just above Any in the input type selection box.)
[6] There is a primitive id function in the menu of the sqrt of block, but we think seeing its (very simple) implementation will make this example easier to understand.
[7] Some languages popular in the “real world” today, such as JavaScript, claim to use prototyping, but their object system is much more complicated than what we are describing (we’re guessing it’s because they were designed by people too familiar with class/instance programming); that has, in some circles, given prototyping a bad name. Our prototyping design comes from Object Logo , and before that, from Henry Lieberman . [Lieberman, H., Using Prototypical Objects to Implement Shared Behavior in Object-Oriented Systems, First Conference on Object-Oriented Programming Languages, Systems, and Applications [OOPSLA-86], ACM SigCHI, Portland, OR, September, 1986. Also in Object-Oriented Computing, Gerald Peterson, Ed., IEEE Computer Society Press, 1987.]
[8] Neighbors are all other sprites whose bounding boxes intersect the doubled dimensions of the requesting sprite’s bounds.